A graph consists of a series of nodes connected by edges. The edges can be either weighted (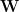

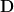


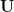
Graph measures can be classified within two broad categories:
- global measures refer to global properties of a graph and, therefore, consist of a single number for each graph;
- nodal measures refer to properties of the nodes of a graph and, therefore, consist of a vector of numbers — one for each node of the graph.
Furthermore, we will indicate to which kind of graph a given measure belongs by using 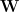
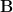
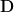
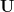
Degree (nodal): Total number of edges connected to a node.
Average degree (global): Average of the degrees of all nodes.
In-degree (nodal, D): Number of inward edges going into a node.
Average in-degree (global, D): Average of the in-degrees of all nodes.
Out-degree (nodal, D): Number of outward edges originating from a node.
Average out-degree (global, D): Average of the out-degrees of all nodes.

Figure 1: Degree of a node. The red node has a high degree (i.e. a large number of connections) while the blue node has a low degree (i.e. a low number of connections).
Methodological notes: For BU graphs, the degree is calculated as the sum of the number of connections across the rows or columns of the connectivity matrix. For BD graphs, the in-degree is calculated as sum over columns, while the out-degree is calculated as sum over the rows; the degree is the sum of in-degree and out-degree. For W graphs, the weights of the connections are ignored in the calculations by binarizing the connectivity matrix so that only edges with nonzero weights are considered connected.
Strength (nodal, W): Sum of the weights of all edges connected to
a node [1].
Average strength (global, W): Average of the strengths of all nodes.
In-strength (nodal, WD): Sum of the weights of inward edges going into a node.
Average in-strength (global, WD): Average of the in-strengths of all nodes.
Out-strength(nodal, WD): Sum of the weights of outward edges originating from a node.
Average out-strength (global, WD): Average of the out- strengths of all nodes.

Figure 2: Strength of a node. Despite having less connections, the red node has a higher strength (only one connection with high strength), while the blue node has a lower strength (it has 7 connections, each with strength of only 0.1).
Methodological notes: For WU graphs, strengths are calculated as sums over either rows or columns of the weighted connectivity matrix. For WD graphs, in-strengths (out-strengths) are calculated as sums over columns (rows), and strengths are calculated as sums of in-strengths and out-strengths.
Eccentricity (nodal): Maximal distance between a certain node and any other node [2].
Average eccentricity (global): Average of the eccentricities of all nodes.
In-eccentricity (nodal, D): Maximal incoming distance from all other nodes to a node.
Average in-eccentricity (global, D): Average of the in-eccentricities of all nodes.
Out-eccentricity (nodal, D): Maximal outgoing distance from a node to all other nodes.
Average out-eccentricity (global, D): Average of the out- eccentricities of all nodes.
Radius (global): Minimum eccentricity of all nodes.
Diameter (global): Maximum eccentricity of all nodes.

Figure 3: Distance between nodes. The distance between the two green nodes is the shortest possible path between them, (e.g. the red path). Other longer paths between the two nodes can also exist (e.g. the blue path).
Methodological notes: The distances (the shortest path lengths) between a node and any other node in the graph can be calculated and stored in a distance matrix. The eccentricity for a node is maximum of all distances calculated for this node. For D graphs, the in-eccentricity (out-eccentricity) is calculated as the maximum along columns (rows) of the distance matrix, the eccentricity is the larger value of the the in-eccentricity and out-eccentricity. For disconnected nodes, the eccentricity is set to NaN.
Path length (nodal): Average distance from a node to all other nodes.
Characteristic path length (global): Average of the path lengths of all nodes.
In-path length (nodal, D): Average distance from all other nodes to a particular node.
Characteristic in-path length (global, D): Average of the in-path lengths of all nodes.
Out-path length (nodal, D): Average distance from a particular node to all other nodes.
Characteristic out-path length (global, D): Average of the out-path lengths of all nodes.
Methodological notes: The distance between two nodes is defined as the length of the shortest path between those nodes (figure 3). For B graphs, the length of a path is the number of edges. For W graphs, the length of an edge is a function of its weight; typically, the edge length is inversely proportional to the edge weight because a
high weight implies a shorter connection [3]. For D graphs, the path length of a node is the average of its in- and out-path lengths. The shortest path lengths between all pairs of nodes can be found using Dijkstra’s algorithm on W graphs and using breadth-first search on binary graphs [4].
Triangles (nodal): Number of neighbors of a node that are also neighbors of each other [5].

Figure 4:Triangles around nodes. The red node has a high number of triangles (only the red edges contribute as the black edges are not connected between themselves), while the blue node has a low number of triangles (only 1 triangle is formed by the blue edges).
Methodological notes: For BU graphs, given a connection matrix 
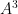

Clustering coefficient (nodal): Fraction of triangles present around a node [6].
Clustering coefficient (global): Average of the clustering coefficients of all nodes.
Methodological notes: The clustering coefficient is calculated as the ratio between the number of triangles present around a node and the maximum number of triangles that could possibly be formed around that node. See also triangles for how the number of triangles is calculated. For U graphs, the total number of possible triangles is calculated as 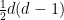
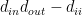

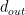
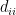
Transitivity (global): The ratio of total number of triangles to the number of (unordered) triplets in the graph.
Methodological notes: The transitivity is calculated as 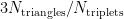


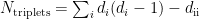
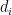

Closeness centrality (nodal): Inverse of the path length of a node.
In-closeness centrality (nodal, D): Inverse of the in-path length of a node.
Out-closeness centrality (nodal, D): Inverse of the out-path length of a node.
Methodological notes: See path length for the calculation of the path length.
Betweenness centrality (nodal): Fraction of all shortest paths in the graph that pass through a node. Nodes with high values of betweenness centrality participate in a large number of shortest paths.

Figure 5: Betweeness centrality of a node. The red node has a high betweeness centrality (many shortest paths that connect the nodes from left to right pass through the red node), while the blue node has a low betweeness centrality (no shortest path
lengths pass through the blue node).
Methodological notes: An algebraic method used to calculate the betweenness centrality is presented by Kintali [8].
Global efficiency (nodal): Average of the inverse shortest path length from a node to all other nodes [9].
Global efficiency (global): Average of the global efficiencies of all nodes.
In-global efficiency (nodal, D): Average of the inverse shortest in-path lengths of a node.
In-global efficiency (global, D): Average of the in-global efficiencies of all nodes.
Out-global efficiency (nodal, D): Average of the inverse shortest out-path lengths of a node.
Out-global efficiency (global, D): Average of the out-global efficiencies of all nodes.
Methodological notes: See path length for the calculation of the path length. After the path lengths from a node to all other nodes are calculated, they are inverted and the average gives the global efficiency for the node. For D graphs, the global efficiencies of the nodes are the average of their in- and out-global efficiencies.
Local efficiency (nodal): Global efficiency of a node calculated on the subgraph created by the node’s neighbors.
Local efficiency (global): Average of the local efficiencies of all nodes.
Methodological notes: See global efficiency for the calculation of the global efficiency. The local efficiency is calculated by applying the same steps on the subgraph formed by the node’s neighbors. In the case of W graph, the weighted connections of the neighbors of node 
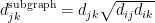
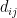
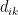
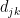
Modularity (global): Extent to which a graph can be divided into clearly separated communities (i.e. or modules). Its calculation requires a previously determined community structure.

Figure 6: High modularity. This graph is composed by 3 clearly separated communities with a high number of within-module connections and a low number of between-module connections.

Figure 7: Low modularity. This graphs is the one shown in Figure \ref{fig:modularity_high} with some extra between-module connections. The graph can no longer be clearly separated into a collection of communities.
Methodological notes: The modularity is calculated as
![\frac{1}{l}\sum_{ij} \left[ A_{ij} -\frac{k_i k_j}{l} \right] \delta_{ij}](http://s0.wp.com/latex.php?latex=%5Cfrac%7B1%7D%7Bl%7D%5Csum_%7Bij%7D+%5Cleft%5B+A_%7Bij%7D+-%5Cfrac%7Bk_i+k_j%7D%7Bl%7D+%5Cright%5D+%5Cdelta_%7Bij%7D&bg=ffffff&fg=000&s=0&c=20201002)
where 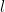

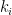

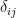


Within-module z-score (nodal): Extent to which a node is connected to the other nodes in the same community. Thus, it is a within-module version of degree. Its calculation requires a previously determined community structure.
Within-module in-z-score (nodal, D): Z-score calculated only by considering the contribution of in-path lengths.
Within-module out-z-score (nodal, D): Z-score calculated only by considering the contribution of out-path lengths.

Figure 8: Within-module z-score. A node can have low z-score because it has a low number of connections (leftmost yellow node) or because it has a lot of connections outside of the community to which it belongs (rightmost yellow node). Nodes with lots of connections within their community have high z-score (e.g. violet node).
Methodological notes: The z-Score is calculated as

where 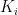
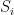
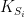

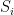
Participation coefficient (nodal): Quantifies the relation between the number of edges connecting a node outside its community and its total number of edges. Its calculation requires a previously determined community structure.

Figure 9: Participation coefficient. A node has low participation coefficient if most of its connections are within its community (violet node). It has high participation coefficient if a lot of its connections are with nodes in different communities (yellow node).
Methodological notes: The participation coefficient can be calculated as
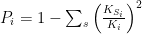
where the sum runs over all communities,
Assortativity coefficient (global): The assortativity coefficient is a correlation coefficient between the degrees/strengths of all nodes on two opposite ends of a link [10].
Methodological notes: The assortativity is calculated as
![r = \frac{l^{-1}\sum_{i,j\in L }k_i k_j - [l^{-1} \sum_{i,j\in L} \frac{1}{2}(k_i + k_j)]^2}{l^{-1} \sum_{i,j\in L} \frac{1}{2}(k_i^2 + k_j^2) - [l^{-1} \sum_{i,j\in L} \frac{1}{2}(k_i + k_j)]^2}](http://s0.wp.com/latex.php?latex=r+%3D+%5Cfrac%7Bl%5E%7B-1%7D%5Csum_%7Bi%2Cj%5Cin+L+%7Dk_i+k_j+-+%5Bl%5E%7B-1%7D+%5Csum_%7Bi%2Cj%5Cin+L%7D+%5Cfrac%7B1%7D%7B2%7D%28k_i+%2B+k_j%29%5D%5E2%7D%7Bl%5E%7B-1%7D+%5Csum_%7Bi%2Cj%5Cin+L%7D+%5Cfrac%7B1%7D%7B2%7D%28k_i%5E2+%2B+k_j%5E2%29+-+%5Bl%5E%7B-1%7D+%5Csum_%7Bi%2Cj%5Cin+L%7D+%5Cfrac%7B1%7D%7B2%7D%28k_i+%2B+k_j%29%5D%5E2%7D&bg=ffffff&fg=000&s=0&c=20201002)
where
Small-worldness (global): A small-world graph has a similar characteristic path lengths as a random graph with the same degree distributio but is significantly more clustered [11].
Methodological notes: The assortativity is calculated as
where